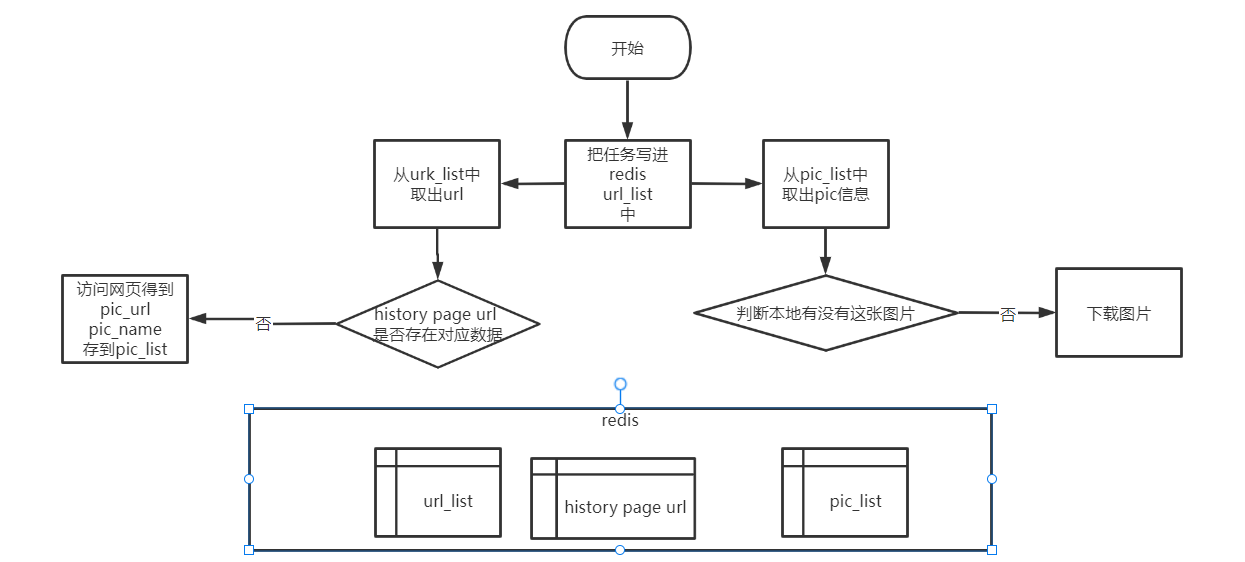
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
|
import os.path
import random
import re
import threading
import time
import requests
import redis
from lxml import etree
proxy_list = []
def get_source_code(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
for i in range(20):
proxy = random.choice(proxy_list) if proxy_list else None
try:
if proxy:
if 'https' in proxy:
proxies = {'https': proxy}
else:
proxies = {'http': proxy}
print("尝试第{}次访问\t{}".format(i + 1, url))
response = requests.request("GET", url, headers=headers, timeout=3,
proxies=proxies)
if response.status_code == 200:
print("访问通过---")
break
else:
print("直接访问")
response = requests.request("GET", url, headers=headers)
except:
pass
if response:
text = response.content.decode('gbk')
data_list = re.findall("<img src=\"http://img.netbian.com/file/\d{4}/\d{4}/small.*?\.jpg\" alt=\".*?\" />",
text)
for data in data_list:
try:
small_pic_url = re.findall("src=\"(.*?)\"", data)[0]
pic_id = re.search(r"/small(.*?)\.jpg", data).groups()[0][:-10]
pic_url = re.sub(re.findall("/(small.*?)\.jpg", small_pic_url)[0], pic_id, small_pic_url)
pic_name = re.findall("alt=\"(.*?)\"", data)[0]
threading.Thread(target=deonload_img, args=(pic_name, pic_url)).start()
except:
print("出现意外。。。")
if url + '\n' not in history:
with open('history.txt', 'a+', encoding='utf-8') as f:
f.writelines(url + '\n')
def deonload_img(img_name, img_url):
global proxy_list
if os.path.exists('img/' + str(img_name) + '.jpg'):
print("已存在,pass")
return
else:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
for i in range(20):
try:
proxy = random.choice(proxy_list) if proxy_list else None
if proxy:
print("尝试第{}次下载图片\t{}".format(i + 1, img_name))
resp = requests.request("GET", img_url, headers=headers, timeout=3,
proxies={'http': proxy, 'https': proxy.replace("http", "https")})
if resp.status_code == 200:
open('img/' + str(img_name) + '.jpg', 'wb').write(resp.content)
print("下载图片成功", img_name)
break
else:
print("直接访问")
resp = requests.get(img_url, headers=headers, stream=True)
if resp.status_code == 200:
open('img/' + str(img_name) + '.jpg', 'wb').write(resp.content)
print("下载图片成功", img_name)
return
except:
pass
with open('img_download_fail.txt', 'a+', encoding='utf-8') as f:
f.writelines(img_name + ' ' + img_url + '\n')
def get_proxy_list():
url = "https://ip.ihuan.me/address/5Lit5Zu9.html"
payload = {}
headers = {
'authority': 'ip.ihuan.me',
'sec-ch-ua': '"Chromium";v="94", "Google Chrome";v="94", ";Not A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'accept-language': 'zh-CN,zh;q=0.9'
}
response = requests.request("GET", url, headers=headers, data=payload)
res = []
_ = etree.HTML(response.text)
type_dct = {
"HTTP": "http://",
"HTTPS": "https://"
}
data_list = _.xpath("//tbody/tr")
for data in data_list:
ip = data.xpath("./td[1]/a/text()")[0]
port = data.xpath("./td[2]/text()")[0]
type = "HTTP"
res.append(type_dct[type] + ip + ':' + port)
return res
def check(proxy):
href = 'https://www.baidu.com'
if 'https' in proxy:
proxies = {'https': proxy}
else:
proxies = {'http': proxy}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4396.0 Safari/537.36'
}
try:
r = requests.get(href, proxies=proxies, timeout=1, headers=headers)
if r.status_code == 200:
return True
except:
return False
def get_proxy():
global proxy_list
p_list = get_proxy_list()
pp_list = []
count = 0
for p in p_list:
if check(p):
pp_list.append(p)
count += 1
proxy_list = pp_list[:]
print("更新了{}个代理".format(count))
def proxy_time_task(inc):
try:
get_proxy()
except:
print("获取代理出现错误,稍后重试。")
t = threading.Timer(inc, proxy_time_task, (20,))
t.start()
if __name__ == '__main__':
with open('task.txt', 'w', encoding='utf-8') as f:
f.writelines('http://www.netbian.com/index.htm' + '\n')
for i in range(2, 1000):
f.writelines("http://www.netbian.com/index_{}.htm".format(i) + '\n')
if not os.path.exists('./img'):
os.mkdir('./img')
proxy_time_task(20)
time.sleep(3)
print("初始化结束")
with open('task.txt', 'r', encoding='utf-8') as f:
task_list = f.readlines()
if not os.path.exists('history.txt'):
history = []
else:
with open('history.txt', 'r', encoding='utf-8') as f:
history = f.readlines()
for url in task_list:
url = url.replace('\r', '').replace('\n', '').strip()
if url + '\n' not in history:
get_source_code(url)
time.sleep(2)
print(url, "done!")
else:
print("已存在,跳过")
|