1
2
3
4
5
6
7
8
| 环境
window10
python3
re
requests
etree
|
源码地址
[TOC]
前言
这次来写一个基础版的获取网络上公开免费壁纸的爬虫,采集的网站为 彼岸桌面 ,网站打开是这个样子:
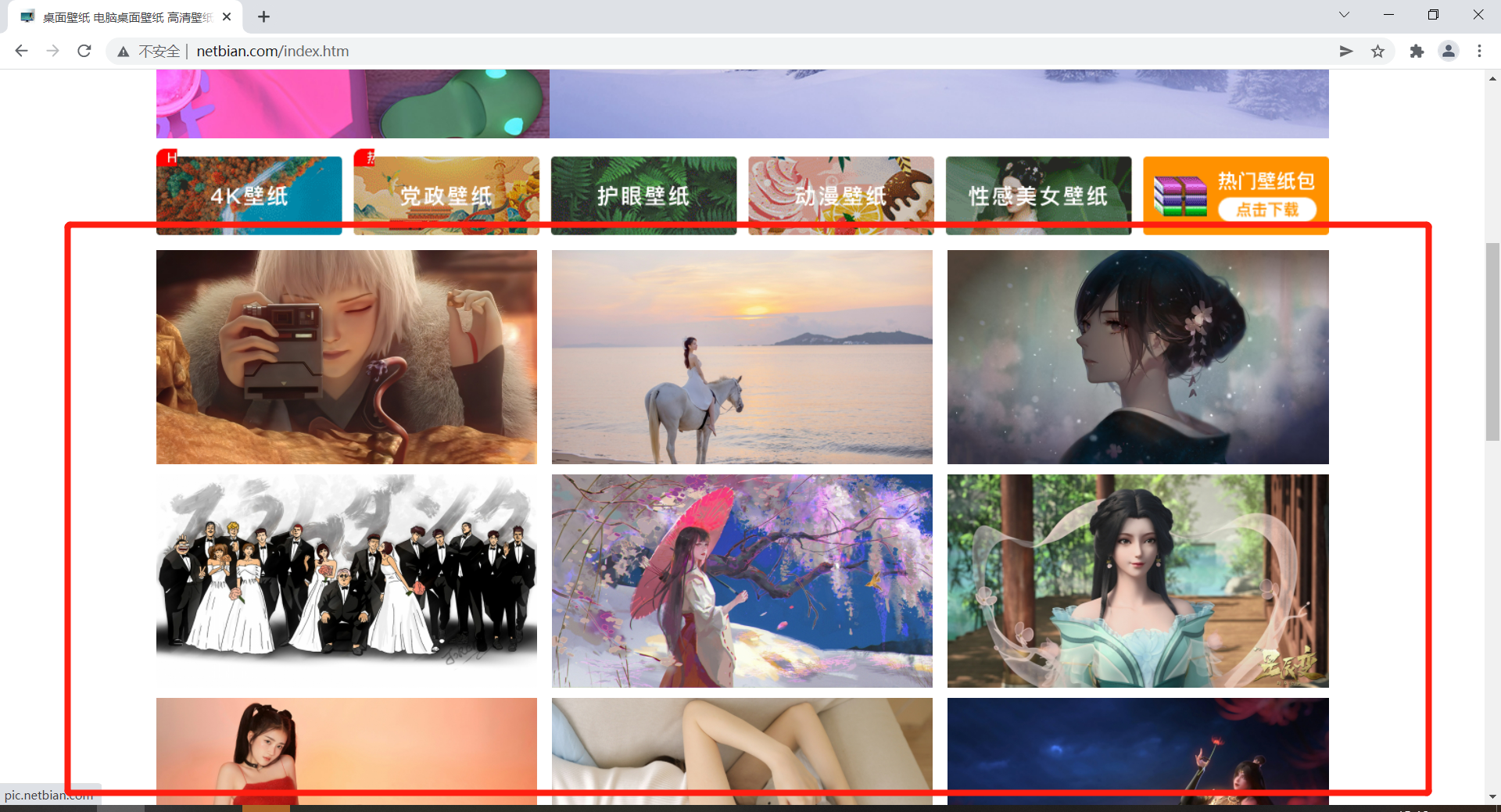
红色框框中为我们这次的目标。
分析网站
以第一页面为例。
通过测试发现,访问网站不需要特殊的请求头或者加密字段,拿到网页源码应该会比较容易。
打开 彼岸桌面 ,第一页红色框框框住的地方总共有20个图片,每张图片又可以通向这张图片的详情页(大图页面),进入大图也可以拿到大图的url,通过目标图片的url,使用一定的方法下载图片下来就可以了。
继续分析并写出相应代码
1 获取网页源码
这个网站的请求不需要特殊的请求头,也没有什么加密,因此用最简单的方法去实现就可以,获取网页源码的方法代码为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| def get_source_code(url):
"""
获取给定url的网页源码
:param url: 要去访问的url
:return:返回该url网页源码,字符串形式
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
response = requests.request("GET", url, headers=headers)
return response.text
|
2 获取图片 url
2.1 这里先做一定的分析,再尝试去写代码。
正常的思路是:
相对应的几个数据

通过这样的比对,我们可以发现,大图和小图的url貌似有一些联系,通过多找几张图片进行比对,发现他们之间大概是这样的关系:

大图url所包含的数据信息,小图全都有,所以我们可以不进入详情页,通过对小图url进行一定的处理直接得到大图的url。

okok,接下来开始写代码。
2.2 通过上次用到的etree解析网页,获取小图的url
1
2
3
4
5
6
| def get_img_url(text):
_ = etree.HTML(text)
data_list = _.xpath("//div[@class='list']//a")
for data in data_list:
small_pic_url = data.xpath("./img/@src")[0]
|
2.3 获取这张图片独特的表示代码pic_id
1
2
3
4
5
| def get_img_url(text):
_ = etree.HTML(text)
data_list = _.xpath("//div[@class='list']//a")
small_pic_url = data.xpath("./img/@src")[0]
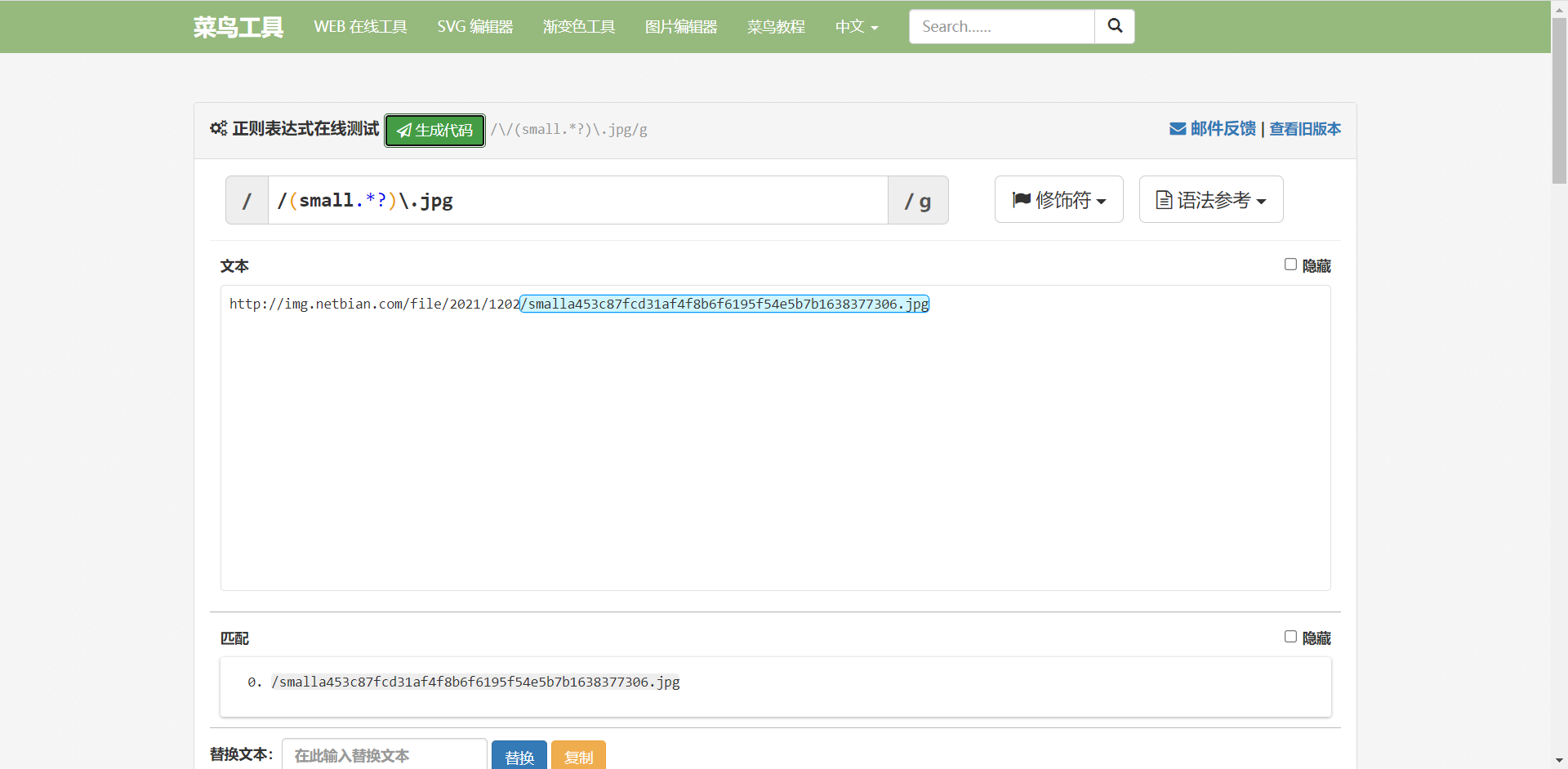
pic_id = re.search(r"/small(.*?)\.jpg",small_pic_url).groups()[0][:-10]
|
关于正则表达式,这次就不展开说了,有机会单独整理归纳出来。
这次推荐一个网址 正则表达式 在线测试 ,有一些常用语法介绍,可以测试正则表达式是否正确,写之前去测一下,还有一些常用语言的代码生成,嗯,本菜猫觉得很赞。
2.4 获取大图的url
1
2
3
4
5
6
7
8
9
| def get_img_url(text):
_ = etree.HTML(text)
data_list = _.xpath("//div[@class='list']//a")
for data in data_list:
small_pic_url = data.xpath("./img/@src")[0]
pic_id = re.search(r"/small(.*?)\.jpg",small_pic_url).groups()[0][:-10]
pic_url = re.sub(re.findall("/(small.*?)\.jpg",small_pic_url)[0],pic_id,small_pic_url)
print("小图地址\t",small_pic_url)
print("大图地址\t",pic_url)
|
2.5 问题的出现与解决
上面的步骤是在网页给出的小图url满足下图的情况下测才能够正常运行的,但是测试发现,页面上会随机出现跳到主页的图片,它并没有详情页,url规则也不满足上面的正则,程序也就拿不到大图的url,并且因此会报错,程序无法继续下去,因此这个地方我们需要进行一定的处理。

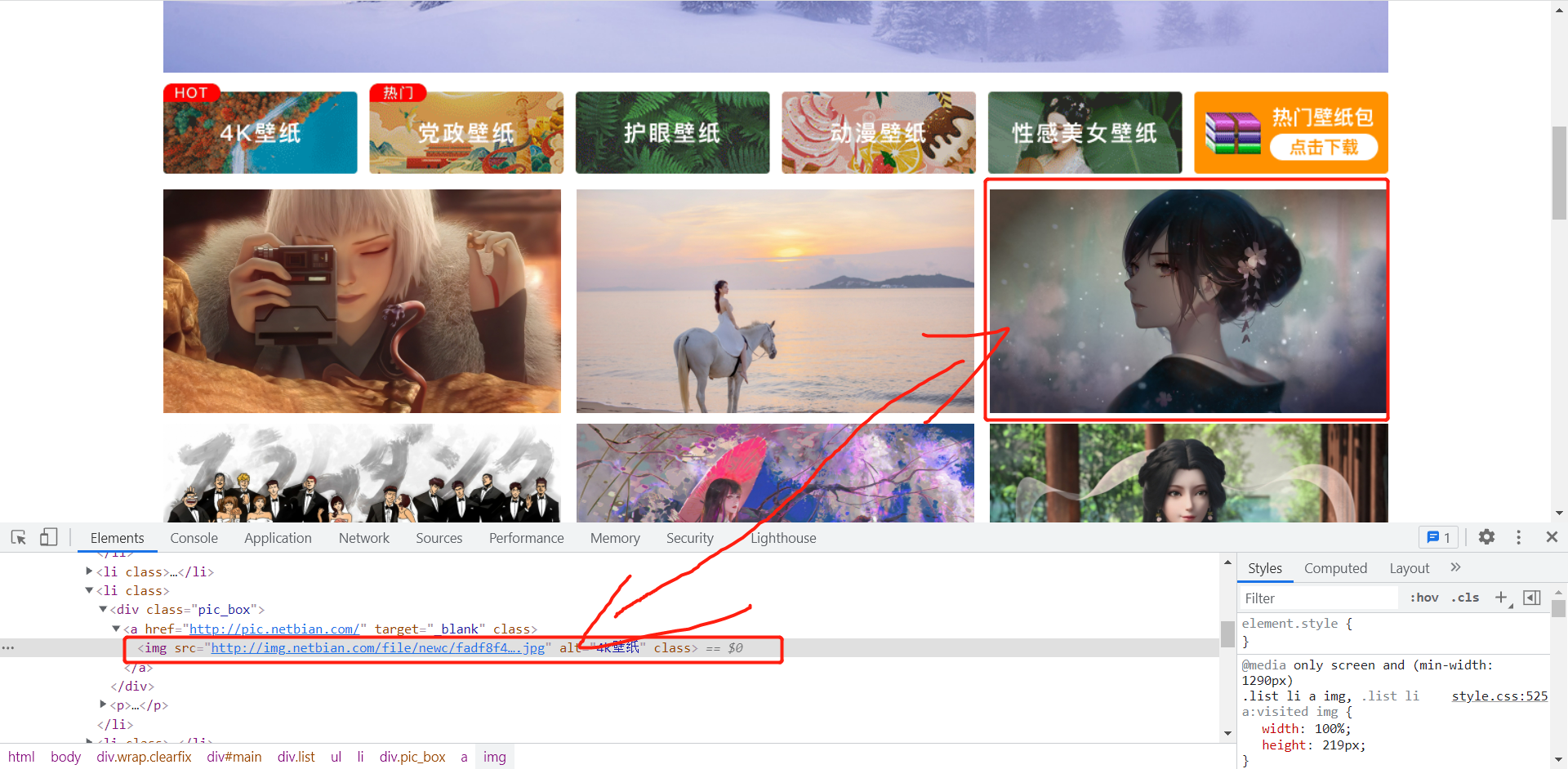
解决办法
这里给出异常处理的代码,如果需要if的版本,自己尝试一下,实在不行评论区留言一下,摸鱼时间会去看一下解决的。
1
2
3
4
5
6
7
8
9
10
11
12
13
| def get_img_url(text):
_ = etree.HTML(text)
data_list = _.xpath("//div[@class='list']//a")
for data in data_list:
print("-" * 100)
try:
small_pic_url = data.xpath("./img/@src")[0]
pic_id = re.search(r"/small(.*?)\.jpg", small_pic_url).groups()[0][:-10]
pic_url = re.sub(re.findall("/(small.*?)\.jpg",small_pic_url)[0],pic_id,small_pic_url)
print("小图地址\t",small_pic_url)
print("大图地址\t",pic_url)
except:
print(data.xpath("./img/@src"),"出错")
|
当然,这里即便是出错了,也可以判断一下,这里如果是一张图片,即使分辨率不够,但是也可以凑活凑活直接就当作大图去下载就是了。这里大家随意就好。
下载图片
下载图片和下载网页源码其实是一个样子的,都是通过访问去吧网页的数据拿下来,只不过网页源码我们是拿到字符串姓氏的数据,方便后米看的处理,而下载图片我们是要写到本地,用字符串写的话那就不是图片应该有的格式了,直接体现就是写到本地的图片打不开。
下面是一个常规的用python的request去拿数据,写图片的操作。
需要先在py文件同级目录建一个名为img的文件夹
1
2
3
4
5
6
7
8
| def download_img(img_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
resp = requests.get(img_url, headers=headers, stream=True)
if resp.status_code == 200:
open('img/' + str(time.time()) + '.jpg', 'wb').write(resp.content)
print("下载图片成功")
|
resp.status_code为网页访问的状态码,一般200为正常访问。这边做了一个判断,只有正常拿数据才会执行写入图片的操作。
存储壁纸的位置为同级目录下的img文件夹,文件名直接以时间戳为名。
完整源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| import re
import time
import requests
from lxml import etree
def get_source_code(url):
"""
获取给定url的网页源码
:param url: 要去访问的url
:return:返回该url网页源码,字符串形式
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
response = requests.request("GET", url, headers=headers)
return response.text
def get_img_url(text):
_ = etree.HTML(text)
data_list = _.xpath("//div[@class='list']//a")
for data in data_list:
print("-" * 100)
try:
small_pic_url = data.xpath("./img/@src")[0]
pic_id = re.search(r"/small(.*?)\.jpg", small_pic_url).groups()[0][:-10]
pic_url = re.sub(re.findall("/(small.*?)\.jpg", small_pic_url)[0], pic_id, small_pic_url)
print("小图地址\t", small_pic_url)
print("大图地址\t", pic_url)
download_img(pic_url)
except:
print(data.xpath("./img/@src"), "出错")
def download_img(img_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
resp = requests.get(img_url, headers=headers, stream=True)
if resp.status_code == 200:
open('img/' + str(time.time()) + '.jpg', 'wb').write(resp.content)
print("下载图片成功")
if __name__ == '__main__':
url = "http://www.netbian.com/index.htm"
source_code = get_source_code(url)
get_img_url(source_code)
|
运行结果
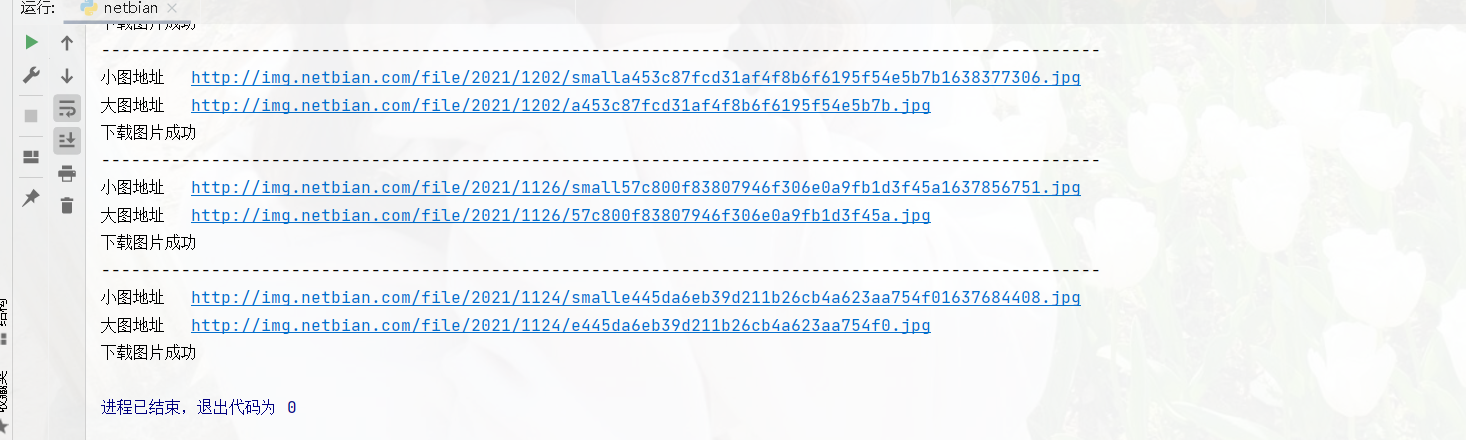
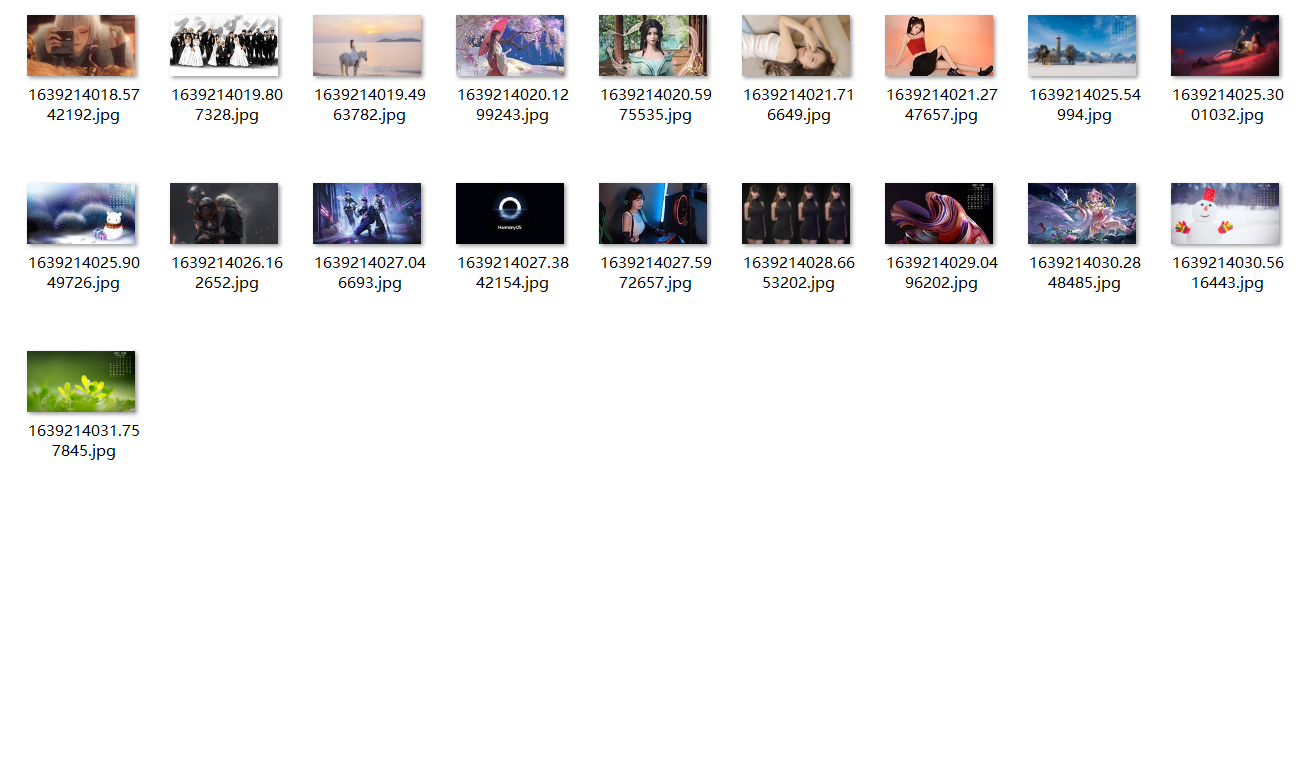
写在最后
这个爬虫有很多不完善的地方,比如:
暂时只写了第一页,后面没写。。。。。。
图片名最好也采集到,不然看到的结果都是一串数字,很奇怪。而且把图片名那下来之后,可以进行一定的分类筛选,比如名称带美女两个字的可以单独放在另外一个文件夹,巴拉巴拉。。。。。。
下载图片的地方需要手动先建一个img的文件夹,否则报错。。。虽然很简单,但是下次改。。。
整个程序基本使用的是顺序结构,单线程运行,下载的速度有待提高(多线程);
如果要访问100,1000页,那程序万一中间停止了,又要从头开始,那不坑爹嘛。加上一个历史功能也是挺有必要的;
要是真的要采集比较多的数量,当网站发发现了我们的异常操作,经常会把我们的ip给拉黑,所以加一个代理也是很有必要的;(测试写了一页,没试过直接搞1000页)
程序的鲁棒性。。。
爬虫仅做学习交流使用。
总之这个爬虫还有很大的优化空间,下次抽点时间完善一下。
实力有限,才疏学浅,如有错误,欢迎指正。




