1
2
3
4
5
6
7
8
| 环境
window10
python3
使用到的库
re 字符串匹配
openpyxl 表格操作
requests 网络请求
lxml 网页源码解析
|
源码地址
步骤
写爬虫之前首先要知道我要怎么写一个爬虫,就像如果要把大象塞进冰箱,也同样思考步骤一样。
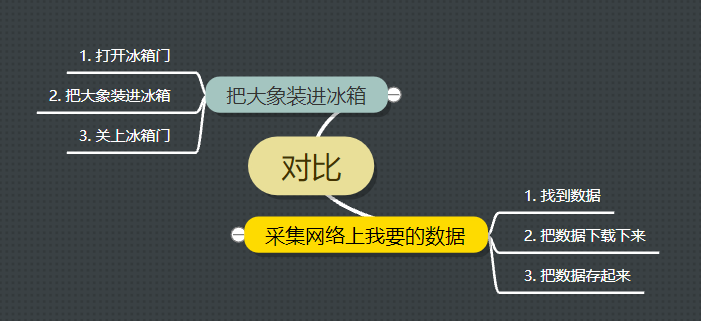
由上图的类比,我们可以有条不紊,步骤清晰的开始写爬虫了。
1 找到数据
首先我们奥找到我们要采集的数据。
1.1 url
这次我们采集的是豆瓣读书的新书榜,也就是 https://book.douban.com/latest 这个网址。设定目标为新书速递10页的全部数据,那第一页的网址我们就已经拿到了,也就是 https://book.douban.com/latest 。
页面拉到最下面,点一下后面一页的页码,进入第二页,发现它的网址发生了一些变化,如下:
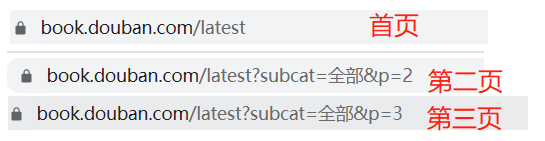
首页之后的网址多了 ?subcat=全部&p=3,结合首页的url,进行合理的推理猜测:
`latest`为最新的意思,即新书速递中的新的意思;
`subcat`大概是 `sub catalogue`,即子目录,`=`后边的全部对应着新书速递页面下面的分类:

猜测首页的url也可以用后面的格式写,即首页的url为:

通过测试,首页的确可以通过这样的方式访问得到。
这里实际的网址为:`https://book.douban.com/latest?subcat=%E5%85%A8%E9%83%A8&p=1`,中文的全部在url传递时候会需要进行编码,这里不展开。
综上,这10页的url地址为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| url_list = []
for i in range(1,11):
url_list.append("https://book.douban.com/latest?subcat=%E5%85%A8%E9%83%A8&p={0}".format(i))
|
1.2 每页具体要拿到的数据
找完了url,接着我们只要搞定其中的一页,那么其他的都一个样子搞就可以了。
网页上显示的元素有:

书名、书籍信息、评分、评价人数。
同样的,每本书要采集的数据都差不多,只要确定写好一个,其他的书也都一样的方式可以拿到。
重复的事情让程序帮我们去做就行了,我们告诉程序怎么去拿就可以。
2 把数据下载下来
2.1 request 请求获取源码
本次采集的数据实在是网页web上的,通过右键网页空白处,查看网页源码,可以看到一堆网页代码,稍微往下拉会发现刚才看到的数据在源码中同样存在着(废话)

所以我们要把网页的源码下载下来。
这里使用python的 requests 库。
获取源码的程序为:
1
2
3
4
5
6
7
8
9
10
| import requests
url = "https://book.douban.com/latest?subcat=%E5%85%A8%E9%83%A8&p=1"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
response = requests.request("GET", url, headers=headers)
print(response.text)
|
实际运行结果为:

可以看到我们拿到了源码。
2.2 解析源码,获取有用信息
源码已经拿到了,需要的数据也在里面,但是就好像我的1000颗玻璃球放在了一个垃圾场里,我能看得到,也能捡起来,但是好麻烦啊。
因此我们需要想办法让源码变得更条理清晰,便于捡玻璃球。
这里用到的是 lxml 中 etree ,将字符串形式的html源码转换为Element对象,之后用xpath进行解析。这里先不做展开,下个爬虫再说。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| import re
import requests
from lxml import etree
url = "https://book.douban.com/latest?subcat=%E5%85%A8%E9%83%A8&p=1"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
response = requests.request("GET", url, headers=headers)
print(response.text)
_ = etree.HTML(response.text)
data_list = _.xpath("//li[contains(@class,'media clearfix')]")
for data in data_list:
print("-" * 100)
book_name = data.xpath(".//h2/a/text()")[0].strip()
book_info = data.xpath(".//p[@class='subject-abstract color-gray']/text()")[0].strip()
score = data.xpath(".//p[@class='clearfix w250']/span[2]/text()")[0].strip()
score_numbers = data.xpath(".//p[@class='clearfix w250']/span[3]/text()")[0]
score_numbers = re.findall("\d+",score_numbers)[0]
print("书名:\t", book_name)
print("书籍信息:\t", book_info)
print("评分:\t", score)
print("评分人数:\t", score_numbers)
|
运行结果:
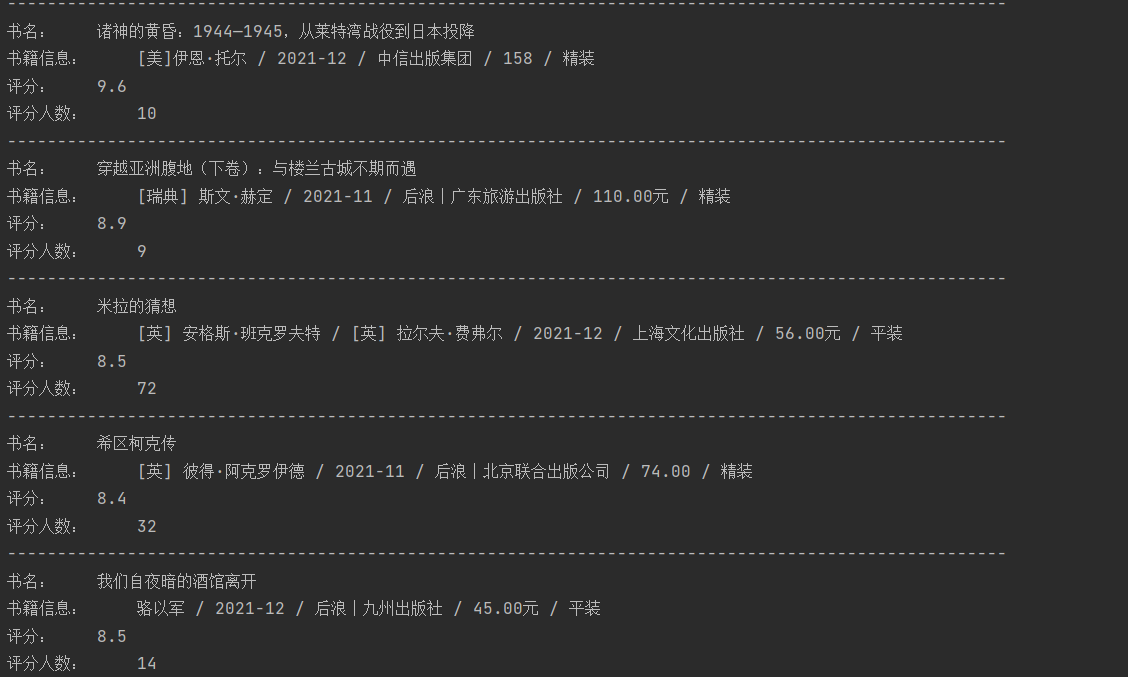
这样我们就拿到了需要的数据。
3 把数据存起来
只是这样把数据都放在黑框框中展示肯定是不行的,还是要找个办法把采集到的数据存起来,这里选择保存到excel中,使用的模块是openpyxl。
3.1 创建新的工作簿获取当前激活的工作表
1
2
3
4
| from openpyxl import Workbook
wb = Workbook()
ws = wb.active
|
3.2 写表头,写数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| ws.cell(1,1).value = "书名"
ws.cell(1,2).value = "书籍信息"
ws.cell(1,3).value = "评分"
ws.cell(1,4).value = "评分人数"
for index,data in enumerate(data_list):
......
print("书名:\t", book_name)
print("书籍信息:\t", book_info)
print("评分:\t", score)
print("评分人数:\t", score_numbers)
ws.cell(2+index,1).value = book_name
ws.cell(2+index,2).value = book_info
ws.cell(2+index,3).value = score
ws.cell(2+index,4).value = score_numbers
|
3.3 保存表格
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| import re
from openpyxl import Workbook
import requests
from lxml import etree
url = "https://book.douban.com/latest?subcat=%E5%85%A8%E9%83%A8&p=1"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
response = requests.request("GET", url, headers=headers)
print(response.text)
_ = etree.HTML(response.text)
wb = Workbook()
ws = wb.active
ws.cell(1,1).value = "书名"
ws.cell(1,2).value = "书籍信息"
ws.cell(1,3).value = "评分"
ws.cell(1,4).value = "评分人数"
data_list = _.xpath("//li[contains(@class,'media clearfix')]")
for index,data in enumerate(data_list):
print("-" * 100)
book_name = data.xpath(".//h2/a/text()")[0].strip()
book_info = data.xpath(".//p[@class='subject-abstract color-gray']/text()")[0].strip()
score = data.xpath(".//p[@class='clearfix w250']/span[2]/text()")[0].strip()
score_numbers = data.xpath(".//p[@class='clearfix w250']/span[3]/text()")[0]
score_numbers = re.findall("\d+",score_numbers)[0]
print("书名:\t", book_name)
print("书籍信息:\t", book_info)
print("评分:\t", score)
print("评分人数:\t", score_numbers)
ws.cell(2+index,1).value = book_name
ws.cell(2+index,2).value = book_info
ws.cell(2+index,3).value = score
ws.cell(2+index,4).value = score_numbers
wb.save('./新书速递.xlsx')
|
执行程序会在当前文件夹下生成新书速递.xlsx文件,文件内容为
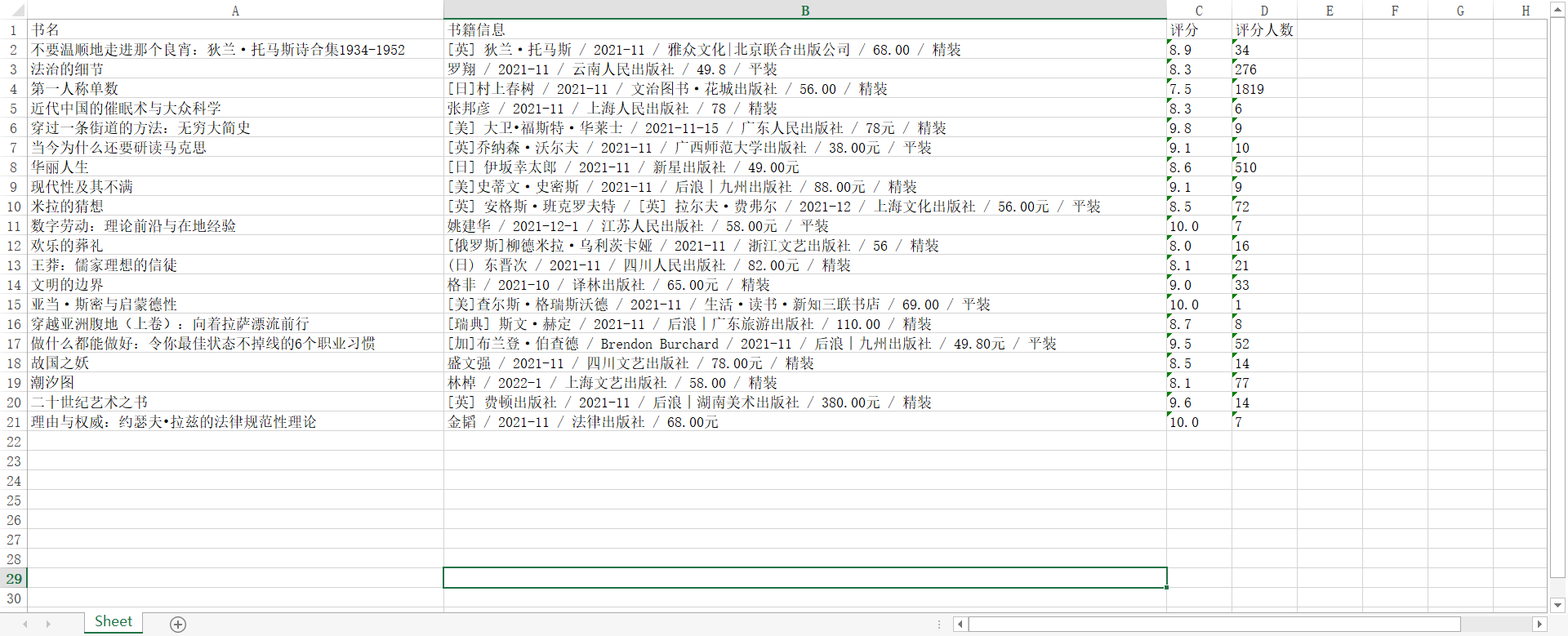
到目前为止,可以拿到第一页我们所需要的信息,但是后面的每一页都要按照这样的方式重新操作一边,这样肯定是太麻烦了,程序到现在能跑,但是还是可以优化一下。
4总结优化
4.1 梳理程序流程
程序整体流程如下
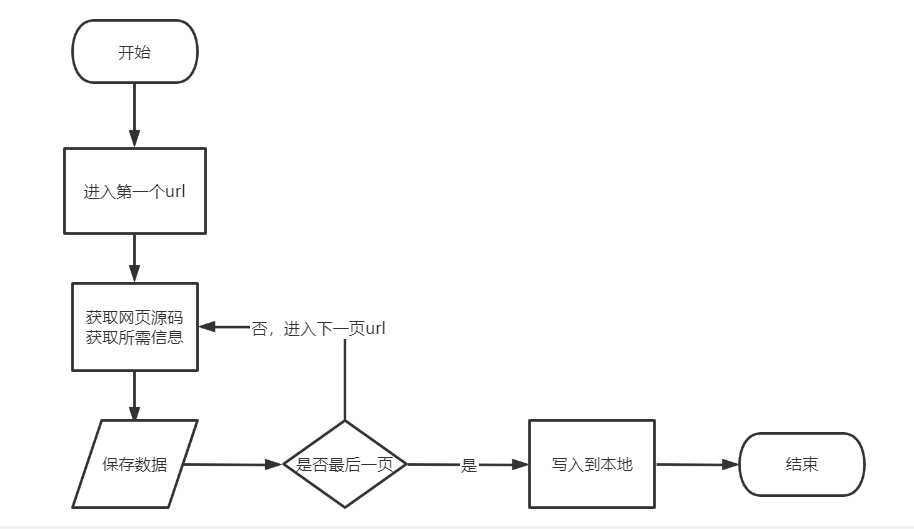
其中,访问网页,保存数据都是多次执行的操作,可以把它写成函数,需要执行的时候调用即可。
4.2 优化
直接上程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
| import re
from openpyxl import Workbook
import requests
from lxml import etree
def get_source_code(url):
"""
获取给定url的网页源码
:param url: 要去访问的url
:return:返回该yrl网页源码,字符串形式
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
response = requests.request("GET", url, headers=headers)
return response.text
def get_info(text):
"""
从字符串的网页源码中获取所需要的信息
:param text: 字符串形式的网页源码
:return: 列表形式的所需要的信息
[
[book_name1,book_info1,score1,score_numbers1],
[book_name2,book_info2,score2,score_numbers2],
[book_name3,book_info3,score3,score_numbers3],
...
]
"""
_ = etree.HTML(text)
data_list = _.xpath("//li[contains(@class,'media clearfix')]")
res = []
for index, data in enumerate(data_list):
print("-" * 100)
book_name = data.xpath(".//h2/a/text()")[0].strip()
book_info = data.xpath(".//p[@class='subject-abstract color-gray']/text()")[0].strip()
score = data.xpath(".//p[@class='clearfix w250']/span[2]/text()")[0].strip()
score_numbers = data.xpath(".//p[@class='clearfix w250']/span[3]/text()")[0]
score_numbers = re.findall("\d+", score_numbers)[0]
res.append([book_name, book_info, score, score_numbers])
return res
def write_to_excel(data_list, path="./新书速递.xlsx"):
"""
将数据写入到同级目录下的execl表格中。
:param data_list: 要写入的数据
:param path: 写入的地址,这地方写死,同级目录下
:return: 输出一个名为 新书速递 的表格文件到本地统计目录下
"""
wb = Workbook()
ws = wb.active
ws.cell(1, 1).value = "书名"
ws.cell(1, 2).value = "书籍信息"
ws.cell(1, 3).value = "评分"
ws.cell(1, 4).value = "评分人数"
for index, data in enumerate(data_list):
ws.cell(2 + index, 1).value = data[0]
ws.cell(2 + index, 2).value = data[1]
ws.cell(2 + index, 3).value = data[2]
ws.cell(2 + index, 4).value = data[3]
wb.save(path)
if __name__ == '__main__':
data_list = []
for i in range(1, 11):
url = "https://book.douban.com/latest?subcat=%E5%85%A8%E9%83%A8&p={0}".format(i)
text = get_source_code(url)
data_list += get_info(text)
write_to_excel(data_list)
|
写在最后
不管是写些什么,开始写之前一定要做好规划。正所谓磨刀不误砍柴工,不管是思考一下流程,还是确定框架,设计模式,都要清楚自己写的每一行代码到底是干嘛的。
这个爬虫实际上还是存在很多问题的,但是我想用这个爬虫来记录一下整个写程序的思路。如果可以,从最后的图片对照着mian函数开始看,一定要清楚每一行代码究竟是在整个程序中扮演者什么角色,执行哪一步操作。
实力有限,才疏学浅,如有错误,欢迎指正。




